Digging into a MongoDB 3.6.20 concurrency bug
What to do when Mongo won’t return your calls
Some time ago, one of our internal users reported a frustrating problem in our ETL job system. One of their jobs got stuck over the weekend, and all attempts to cancel it had no effect. It was the third weekend in a row that this had happened.
We use MongoDB to store the metadata for these jobs, as its document structure makes it a good fit for describing heterogeneous jobs with varying numbers of (and types of) steps. The Java server running the job was still online and responding to requests, but a jstack showed that the job thread was hung waiting on a response from MongoDB. All it was trying to do was update a single field in the Mongo document, but it was waiting forever for a response. From the MongoDB side, the primary node was also aware of the same update: the connection showed up in db.currentOp() and was marked “active”. Terminating the query from the Mongo shell instantly caused the Java thread to throw an exception, so it wasn’t a communication problem. Both sides of the connection were alive, yet the update wasn’t making any progress!
Not good.
Albert investigated and found that our weekly secondary rotation jobs are scheduled around the same time that the group of UPDATE commands fired. Comparing timestamps in the rotation job output strongly suggested that UPDATE commands issued during a replSetReconfigure will hang and never return.
I started trying to reproduce the issue locally by mimicking the problematic UPDATEs and was surprised to find that my very simple Python script experienced the same problem:
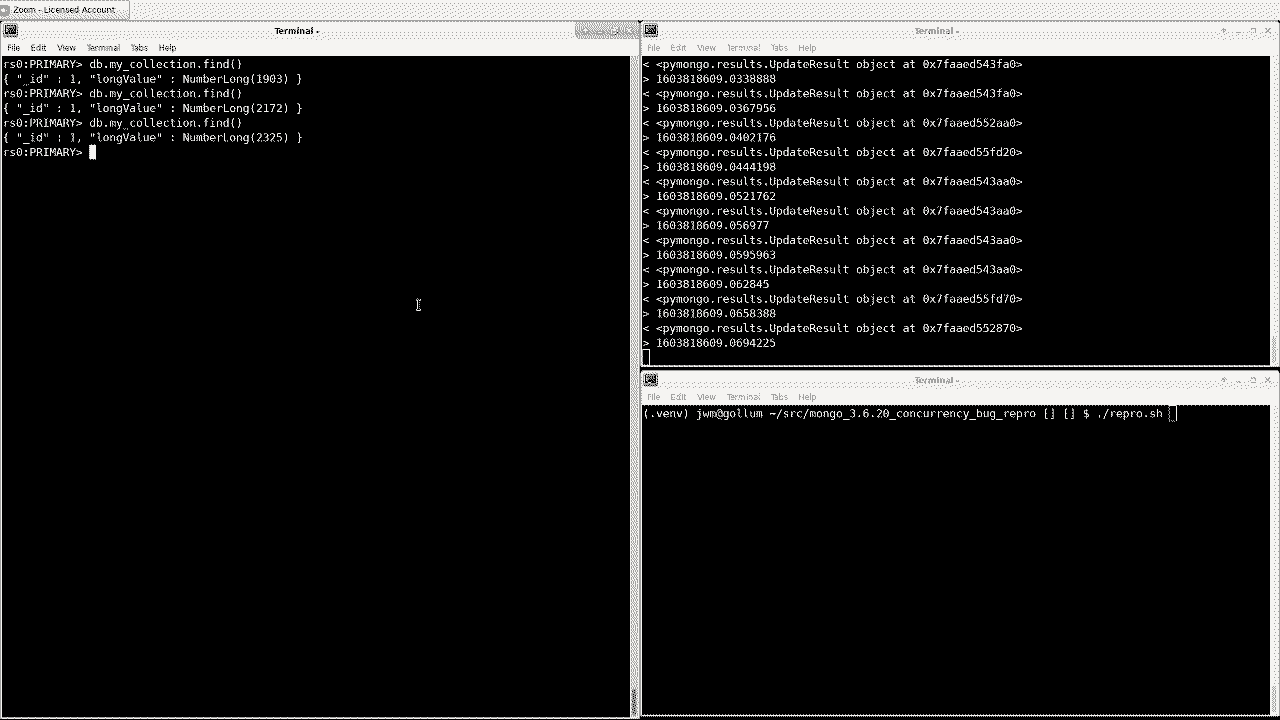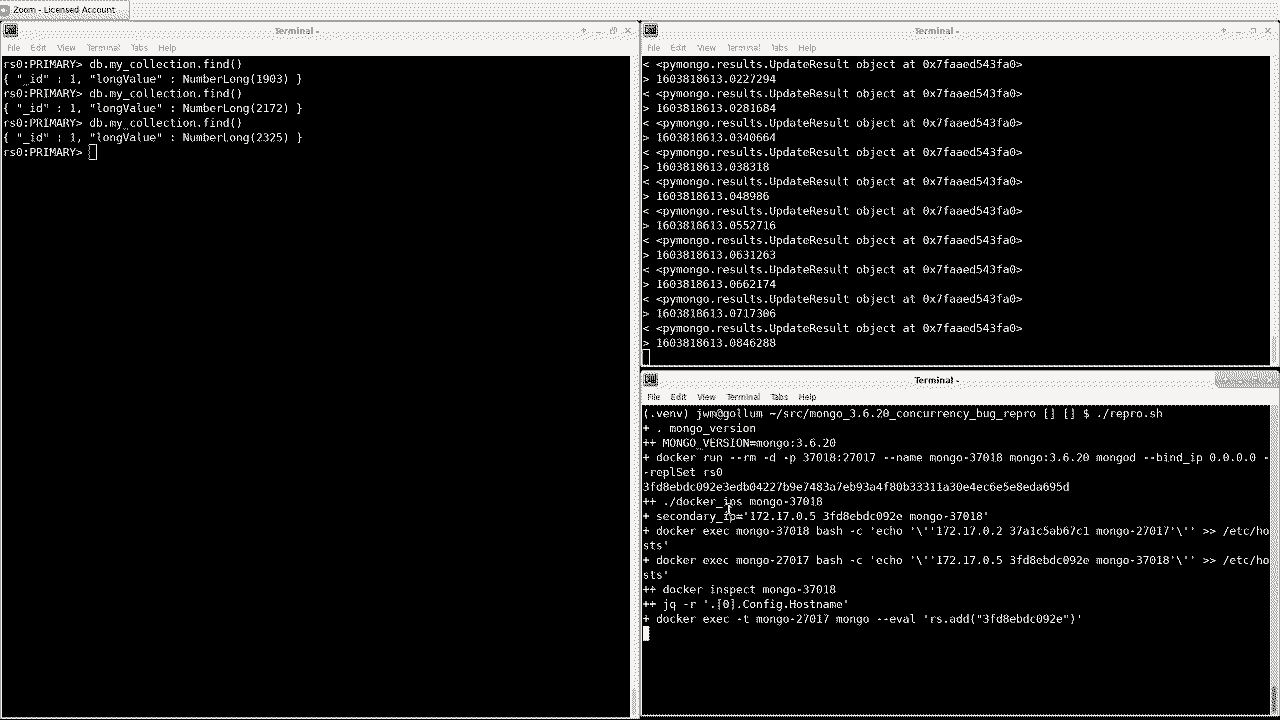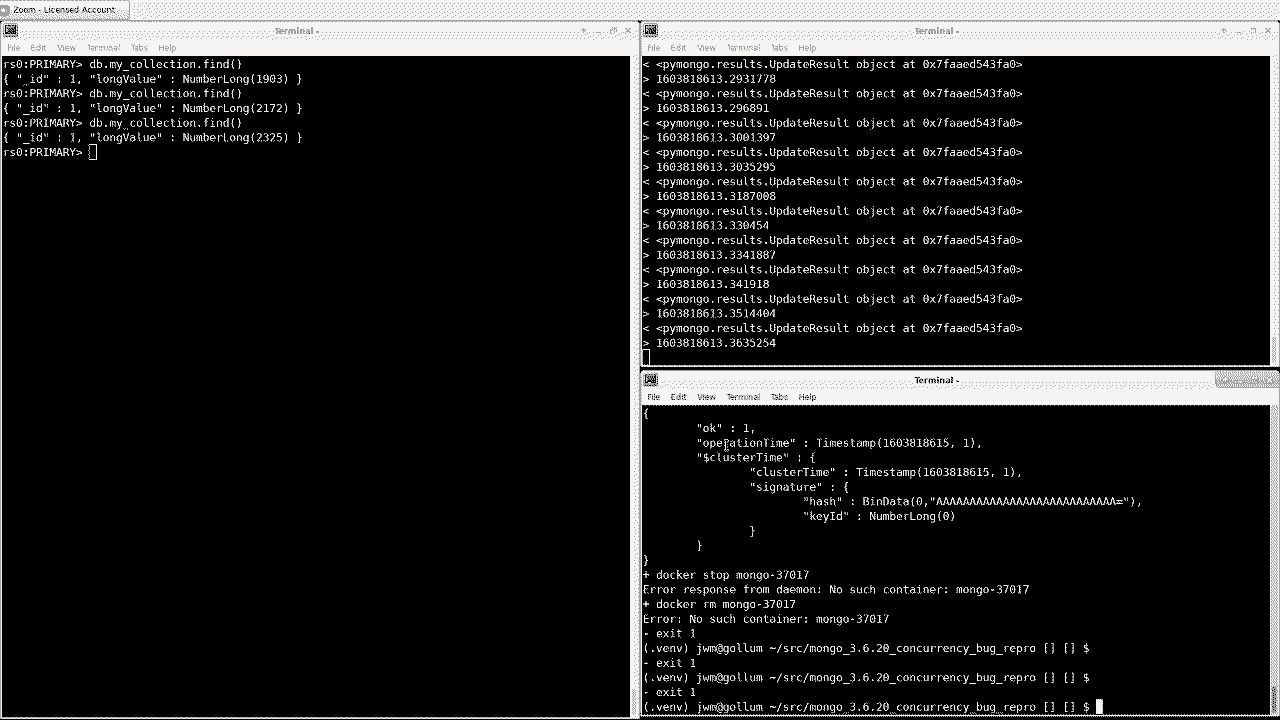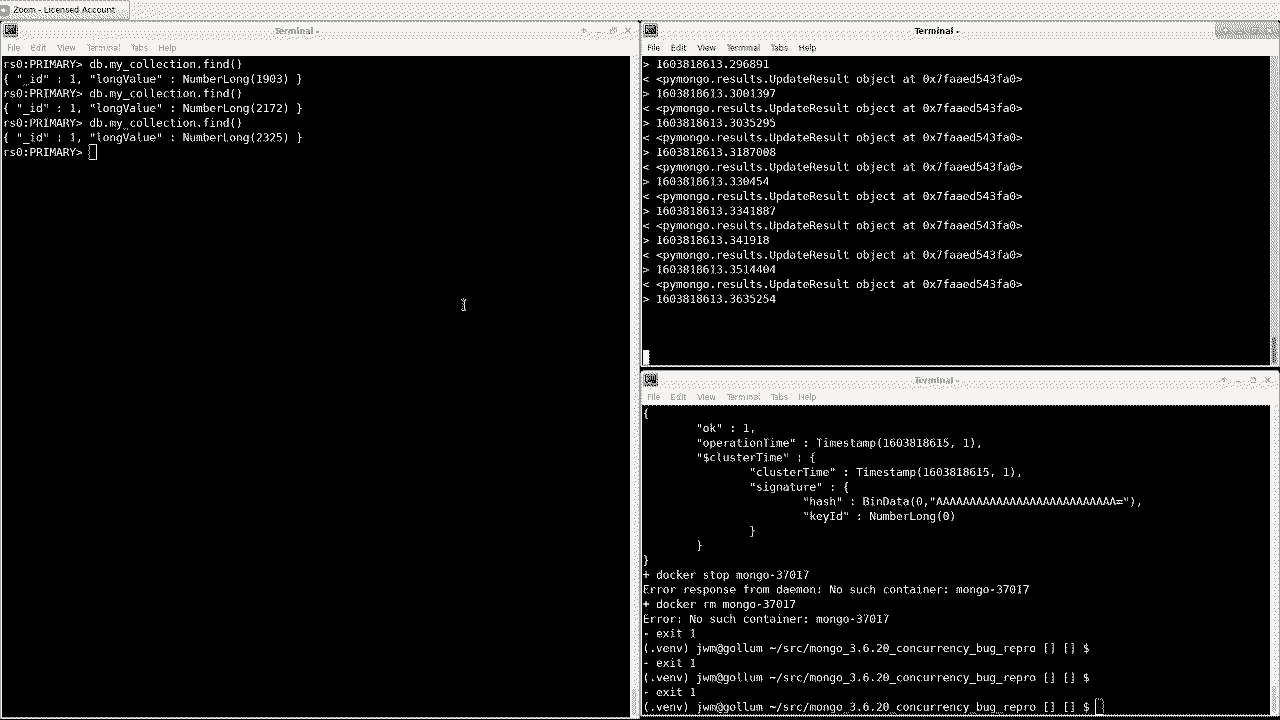
I’ve pushed up scripts that I used to reproduce this issue here.
The fact that I could reproduce the issue with a simple Python script meant that it’s not something to do with any code we’ve written on top of the Java Mongo client. The reproduction test case was so straight forward I turned my sights on MongoDB itself.
Background
This post assumes that you know a little about MongoDB: what a primary and secondary is, what replication is and how it works, what an operation is, and so on.
MongoDB is written in C++ so it’s useful to have a little knowledge there.
MongoDB takes a long time to build
My Vena-issued T480s has a 4 core i5-8350U (with hyper-threading off), 24GB of DDR4 RAM, a modern NVMe drive, and it still takes gollum 33 minutes to build mongod and the mongo CLI binaries.
scons: done building targets.
real 33m42.499s
user 119m10.756s
sys 7m56.016s
Also, did you know that an optimized mongod binary (when statically linked) is around 1.3G? I didn’t either, and now you know.
jwm@gollum ~/opt/mongo [39c200878284912f19553901a6fea4b31531a899] [] $ ls -lh mongod
-rwxr-xr-x 1 jwm jwm 1.3G Oct 21 17:23 mongod
Note: that SHA is for 3.6.20, our production cluster version.
Hello gdb, my old friend
After building the debug binaries, I created a docker container using the resulting mongod and mongo binaries, and confirmed that the issue was still reproducible.
I reproduced the issue and used db.currentOp() to find the connection id (“conn15” in the example below):
...
{
"host" : "ecb589a5d43b:27017",
"desc" : "conn15",
"connectionId" : 15,
"client" : "172.17.0.1:36012",
"clientMetadata" : {
"driver" : {
"name" : "PyMongo",
"version" : "3.11.0"
},
...
},
"active" : true,
...
Then I attached gdb to the primary mongod process and found the corresponding thread:
(gdb) info threads
...
75 Thread 0x7ff5f8bfb700 (LWP 4427) "conn15" futex_wait_cancelable (private=0, expected=0, futex_word=0x7ff5f8bf8a6c)
at ../sysdeps/unix/sysv/linux/futex-internal.h:88
...
(gdb) thread 75
[Switching to thread 75 (Thread 0x7ff5f8bfb700 (LWP 4427))]
#0 futex_wait_cancelable (...) at ../sysdeps/unix/sysv/linux/futex-internal.h:88
88 in ../sysdeps/unix/sysv/linux/futex-internal.h
(gdb) bt
#0 futex_wait_cancelable (...) at ../sysdeps/unix/sysv/linux/futex-internal.h:88
#1 __pthread_cond_wait_common (...) at pthread_cond_wait.c:502
#2 __pthread_cond_wait (...) at pthread_cond_wait.c:655
#3 0x00007ff62ce983bc in std::condition_variable::wait(...) ()
from target:/usr/lib/x86_64-linux-gnu/libstdc++.so.6
#4 0x00005620ed95c4f8 in mongo::OperationContext::<lambda()>::operator()(void) const (__closure=0x7ff5f8bf8890)
at src/mongo/db/operation_context.cpp:313
#5 0x00005620ed95c86f in mongo::OperationContext::waitForConditionOrInterruptNoAssertUntil (...) at src/mongo/db/operation_context.cpp:317
#6 0x00005620ec4cc511 in mongo::repl::ReplicationCoordinatorImpl::_awaitReplication_inlock (...)
at src/mongo/db/repl/replication_coordinator_impl.cpp:1689
#7 0x00005620ec4cba58 in mongo::repl::ReplicationCoordinatorImpl::awaitReplication (...) at src/mongo/db/repl/replication_coordinator_impl.cpp:1581
#8 0x00005620ec049e9f in mongo::waitForWriteConcern (...)
at src/mongo/db/write_concern.cpp:231
#9 0x00005620ebf46fe1 in mongo::(anonymous namespace)::_waitForWriteConcernAndAddToCommandResponse (...) at src/mongo/db/service_entry_point_mongod.cpp:300
#10 0x00005620ebf47847 in mongo::(anonymous namespace)::<lambda()>::operator()(void) const (__closure=0x7ff5f8bf9068)
at src/mongo/db/service_entry_point_mongod.cpp:507
#11 0x00005620ebf4e750 in mongo::ScopeGuardImpl0<mongo::(anonymous namespace)::runCommandImpl(...)::<lambda()> >::Execute(void) (
this=0x7ff5f8bf9060) at src/mongo/util/scopeguard.h:142
#12 0x00005620ebf4e594 in mongo::ScopeGuardImplBase::SafeExecute<mongo::ScopeGuardImpl0<mongo::(anonymous namespace)::runCommandImpl(...)::<lambda()> > >(mongo::ScopeGuardImpl0<mongo::(anonymous namespace)::runCommandImpl(...)::<lambda()> > &) (j=...) at src/mongo/util/scopeguard.h:101
#13 0x00005620ebf4e40e in mongo::ScopeGuardImpl0<mongo::(anonymous namespace)::runCommandImpl(...)::<lambda()> >::~ScopeGuardImpl0(void) (
this=0x7ff5f8bf9060, __in_chrg=<optimized out>) at src/mongo/util/scopeguard.h:138
#14 0x00005620ebf4816f in mongo::(anonymous namespace)::runCommandImpl (...)
at src/mongo/db/service_entry_point_mongod.cpp:509
#15 0x00005620ebf49fdc in mongo::(anonymous namespace)::execCommandDatabase (...)
at src/mongo/db/service_entry_point_mongod.cpp:768
#16 0x00005620ebf4b049 in mongo::(anonymous namespace)::<lambda()>::operator()(void) const (__closure=0x7ff5f8bf9740)
at src/mongo/db/service_entry_point_mongod.cpp:882
#17 0x00005620ebf4b82d in mongo::(anonymous namespace)::runCommands (...)
at src/mongo/db/service_entry_point_mongod.cpp:895
...The conn15 thread was stuck waiting on a condition variable at src/mongo/db/operation_context.cpp, line 313, which is frame 4 in the above backtrace:
311 const auto waitStatus = [&] {
312 if (Date_t::max() == deadline) {
313 cv.wait(m);
314 return stdx::cv_status::no_timeout;
315 }
316 return getServiceContext()->getPreciseClockSource()->waitForConditionUntil(cv, m, deadline);
317 }(); Note this op doesn’t have write concern timeout, so the deadline is Date_t::max(). I interpreted this as “if our operation has no deadline, wait forever for the condition variable”.
Frame 5 is the lambda execution, and frame 6 is the calling context: src/mongo/db/repl/replication_coordinator_impl.cpp:1689 is from a loop in a function called _awaitReplication_inlock:
1679 // Must hold _mutex before constructing waitInfo as it will modify _replicationWaiterList
1680 stdx::condition_variable condVar;
1681 ThreadWaiter waiter(opTime, &writeConcern, &condVar);
1682 WaiterGuard guard(&_replicationWaiterList, &waiter);
1683 while (!_doneWaitingForReplication_inlock(opTime, minSnapshot, writeConcern)) {
...
1689 auto status = opCtx->waitForConditionOrInterruptNoAssertUntil(condVar, *lock, wTimeoutDate);
1690 if (!status.isOK()) {
1691 return status.getStatus();
1692 }
...
1710 } The condition variable created here (the one we’re waiting on in frame 4) is passed both to ThreadWaiter waiter and opCtx->waitForConditionOrInterruptNoAssertUntil(...).
Let’s look at ThreadWaiter:
486 // When ThreadWaiter gets notified, it will signal the conditional variable.
487 //
488 // This is used when a thread wants to block inline until the opTime is reached with the given
489 // writeConcern.
490 struct ThreadWaiter : public Waiter {The ThreadWaiter is passed to a WaiterGuard on line 1682, so let’s also look at WaiterGuard:
206 class ReplicationCoordinatorImpl::WaiterGuard {
207 public:
208 /**
209 * Constructor takes the list of waiters and enqueues itself on the list, removing itself
210 * in the destructor.
211 *
212 * Usually waiters will be signaled and removed when their criteria are satisfied, but
213 * wait_until() with timeout may signal waiters earlier and this guard will remove the waiter
214 * properly.
215 *
216 * _list is guarded by ReplicationCoordinatorImpl::_mutex, thus it is illegal to construct one
217 * of these without holding _mutex
218 */
_doneWaitingForReplication_inlock does what you’d imagine – for an op with write concern majority, it waits for the majority of mongo instances to reach the op’s opTime:
1527 bool ReplicationCoordinatorImpl::_doneWaitingForReplication_inlock(
1528 const OpTime& opTime, Timestamp minSnapshot, const WriteConcernOptions& writeConcern) {
...
1569 StatusWith<ReplSetTagPattern> tagPattern = _rsConfig.findCustomWriteMode(patternName);
1570 if (!tagPattern.isOK()) {
1571 return true;
1572 }
1573 return _topCoord->haveTaggedNodesReachedOpTime(opTime, tagPattern.getValue(), useDurableOpTime);
1574 } Based on those snippets, here was the mental model I had so far:
- there’s a list of waiters in
_replicationWaiterList - these waiters refer to condition variables
- if
_doneWaitingForReplication_inlockreturns false, then the thread waits on the condition variable - once the condition variable is notified, the thread wakes up and checks if replication is done again.
I assumed those condition variables would be notified as opTimes on other mongo instances change, but it looks like they are notified when the instance they’re running on has committed a new opTime or something called a committed snapshot. Both _updateLastCommittedOpTime_inlock and _updateCommittedSnapshot_inlock call _wakeReadyWaiters_inlock:
3385 void ReplicationCoordinatorImpl::_updateLastCommittedOpTime_inlock() {
...
3389 // Wake up any threads waiting for replication that now have their replication
3390 // check satisfied. We must do this regardless of whether we updated the lastCommittedOpTime,
3391 // as lastCommittedOpTime may be based on durable optimes whereas some waiters may be
3392 // waiting on applied (but not necessarily durable) optimes.
3393 _wakeReadyWaiters_inlock();
3394 _signalStepDownWaiterIfReady_inlock();
3395 }
...
3805 void ReplicationCoordinatorImpl::_updateCommittedSnapshot_inlock(
3806 const OpTime& newCommittedSnapshot) {
...
3834 // Wake up any threads waiting for read concern or write concern.
3835 _wakeReadyWaiters_inlock();
3836 }
...
3174 void ReplicationCoordinatorImpl::_wakeReadyWaiters_inlock() {
3175 _replicationWaiterList.signalAndRemoveIf_inlock([this](Waiter* waiter) {
3176 return _doneWaitingForReplication_inlock(
3177 waiter->opTime, Timestamp(), *waiter->writeConcern);
3178 });
3179 } Note that in _wakeReadyWaiters_inlock, the ThreadWaiter is removed from _replicationWaiterList if replication is done. This makes sense – that thread won’t need to wait ever again.
I wanted to print out the ThreadWaiter object information, but:
(gdb) frame 6
(gdb) print _replicationWaiterList._list.size()
$13 = 0
No more waiters! We’ve reached a state where there are no waiters in _replicationWaiterList but we’re still waiting on the condition variable to be notified. That means:
- after the thread woke up,
_doneWaitingForReplication_inlockreportedfalse, because we entered another iteration of the loop. - nothing else will notify this thread’s condition variable because the reference to it was gone
This explains what we’re seeing: operations that never return.
So what removes waiters from this list?
~WaiterGuard()ReplicationCoordinatorImpl::_wakeReadyWaiters_inlockReplicationCoordinatorImpl::shutdownReplicationCoordinatorImpl::_updateMemberStateFromTopologyCoordinator_inlock
The last two seemed related to primary stepdowns, and that’s not something we see in this case. This bug is triggered when secondaries are rotated out – nothing affects the primary.
One hypothesis I had was that when a secondary goes away, corresponding waiters are removed from this list, but I scrapped it because replication shouldn’t rely on a designated secondary – any secondary should be able to report that its opTime is up to date and satisfy replication criteria.
Our procedure for rotating secondaries is straight from Mongo’s documentation (https://docs.mongodb.com/manual/tutorial/remove-replica-set-member/) where we:
- Provision a new secondary.
- Run
rs.add(new secondary)on the primary. - Shut down mongod on the instance to be removed.
- Run
rs.remove(old secondary)on the primary.
rs.remove() is an alias that calls the replSetReconfig admin command with a new configuration that no longer contains the instance to be removed.
Issuing that admin command creates another thread that runs ReplicationCoordinatorImpl::processReplSetReconfig. There’s a lot of machinery in there for validating the configuration update (among other things) and if all those are ok, ReplicationCoordinatorImpl::_finishReplSetReconfig is called.
It’s a concurrency bug!
Looking at _finishReplSetReconfig, there’s a lot of code in there to deal with a potential leader election (any replSetReconfig can trigger a primary stepdown and subsequent leader election). If that is cut out, the code looks like the following:
2491 void ReplicationCoordinatorImpl::_finishReplSetReconfig(
2492 const executor::TaskExecutor::CallbackArgs& cbData,
2493 const ReplSetConfig& newConfig,
2494 const bool isForceReconfig,
2495 int myIndex,
2496 const executor::TaskExecutor::EventHandle& finishedEvent) {
...
2530 const ReplSetConfig oldConfig = _rsConfig;
2531 const PostMemberStateUpdateAction action =
2532 _setCurrentRSConfig_inlock(opCtx.get(), newConfig, myIndex);
2533
2534 // On a reconfig we drop all snapshots so we don't mistakenly read from the wrong one.
2535 // For example, if we change the meaning of the "committed" snapshot from applied -> durable.
2536 _dropAllSnapshots_inlock();
...
2549 } Following _setCurrentRSConfig_inlock, there’s again a lot of validation logic in there, and some extra logic for dealing with protocol version changes. If we cut out that code again, the code looks like the following:
3007 ReplicationCoordinatorImpl::_setCurrentRSConfig_inlock(OperationContext* opCtx,
3008 const ReplSetConfig& newConfig,
3009 int myIndex) {
...
3164 // Update commit point for the primary. Called by every reconfig because the config
3165 // may change the definition of majority.
3166 //
3167 // On PV downgrade, commit point is probably still from PV1 but will advance to an OpTime with
3168 // term -1 once any write gets committed in PV0.
3169 _updateLastCommittedOpTime_inlock();
3170
3171 return action;
3172 } _updateLastCommittedOpTime_inlock is one of the functions that calls _wakeReadyWaiters_inlock, which removes waiters from _replicationWaiterList if they are done waiting for replication. Here’s that code again:
3174 void ReplicationCoordinatorImpl::_wakeReadyWaiters_inlock() {
3175 _replicationWaiterList.signalAndRemoveIf_inlock([this](Waiter* waiter) {
3176 return _doneWaitingForReplication_inlock(
3177 waiter->opTime, Timestamp(), *waiter->writeConcern);
3178 });
3179 } The update operation’s waiter is only signaled and removed if _doneWaitingForReplication_inlock returned true for that particular waiter. In the update operation’s thread, execution would proceed after cv.wait(), and eventually reach another _doneWaitingForReplication_inlock in _awaitReplication_inlock:
1681 ThreadWaiter waiter(opTime, &writeConcern, &condVar);
1682 WaiterGuard guard(&_replicationWaiterList, &waiter);
1683 while (!_doneWaitingForReplication_inlock(opTime, minSnapshot, writeConcern)) { If the first _doneWaitingForReplication_inlock returned true and the second returned false the update thread will hang on that condition variable’s wait and (because _wakeReadyWaiters_inlock removes the waiter from the list) there’s nothing that will notify it.
Both _doneWaitingForReplication_inlock calls above reference the same arguments except for the second one: it’s referring to Timestamp() and minSnapshot respectively. What could make it return true then false?
Having another look at _doneWaitingForReplication_inlock, I spotted:
1544 if (writeConcern.wMode == WriteConcernOptions::kMajority) {
1545 if (_externalState->snapshotsEnabled() && !testingSnapshotBehaviorInIsolation) {
1546 // Make sure we have a valid "committed" snapshot up to the needed optime.
1547 if (!_currentCommittedSnapshot) {
1548 return false;
1549 } But back in _finishReplSetReconfig, snapshots are dropped!
2534 // On a reconfig we drop all snapshots so we don't mistakenly read from the wrong one.
2535 // For example, if we change the meaning of the "committed" snapshot from applied -> durable.
2536 _dropAllSnapshots_inlock();
3843 void ReplicationCoordinatorImpl::_dropAllSnapshots_inlock() {
3844 _currentCommittedSnapshot = boost::none;
3845 _externalState->dropAllSnapshots();
3846 } This looked like a concurrency bug!
I confirmed it with a lot of extra Mongo log statements:
2020-10-21T15:07:36.344+0000 E REPL [conn17] ReplicationCoordinatorImpl::WaiterList::add_inlock { opTime: { ts: Timestamp(1603292856, 3), t: 1 }, writeConcern: { w: "majority", j: true, wtimeout: 0 } }
2020-10-21T15:07:36.344+0000 E REPL [conn17] ReplicationCoordinatorImpl::_doneWaitingForReplication_inlock: [opTime { ts: Timestamp(1603292856, 3), t: 1 }, minSnapshot Timestamp(0, 0), writeConcern { w: "majority", j: true, wtimeout: 0 }] !_currentCommittedSnapshot, returning false
2020-10-21T15:07:36.344+0000 E REPL [conn17] looping for 1551, waiters length 1
2020-10-21T15:07:36.344+0000 E REPL [conn17] { opTime: { ts: Timestamp(1603292856, 3), t: 1 }, writeConcern: { w: "majority", j: true, wtimeout: 0 } }
2020-10-21T15:07:38.208+0000 I REPL [replexec-7] New replica set config in use: { _id: "rsvena0", version: 3, protocolVersion: 1, members: [ { _id: 0, host: "736f4cdb52d9:27017", arbiterOnly: false, buildIndexes: true, hidden: false, priority: 1.0, tags: {}, slaveDelay: 0, votes: 1 }, { _id: 2, host: "281b53d51585:27017", arbiterOnly: false, buildIndexes: true, hidden: false, priority: 1.0, tags: {}, slaveDelay: 0, votes: 1 }, { _id: 3, host: "acff78f7f7f1:27017", arbiterOnly: false, buildIndexes: true, hidden: false, priority: 1.0, tags: {}, slaveDelay: 0, votes: 1 } ], settings: { chainingAllowed: true, heartbeatIntervalMillis: 2000, heartbeatTimeoutSecs: 10, electionTimeoutMillis: 10000, catchUpTimeoutMillis: -1, catchUpTakeoverDelayMillis: 30000, getLastErrorModes: {}, getLastErrorDefaults: { w: 1, wtimeout: 0 }, replicaSetId: ObjectId('5f904dd902040f0b89191bc0') } }
2020-10-21T15:07:38.210+0000 E REPL [replexec-7] ReplicationCoordinatorImpl::_doneWaitingForReplication_inlock: [opTime { ts: Timestamp(1603292856, 3), t: 1 }, minSnapshot Timestamp(0, 0), writeConcern { w: "majority", j: true, wtimeout: 0 }] haveTaggedNodesReachedOpTime returned true
2020-10-21T15:07:38.210+0000 E REPL [replexec-7] ReplicationCoordinatorImpl::WaiterList::signalAndRemoveIf_inlock { opTime: { ts: Timestamp(1603292856, 3), t: 1 }, writeConcern: { w: "majority", j: true, wtimeout: 0 } }
2020-10-21T15:07:38.210+0000 I CONTROL [replexec-7] ReplicationCoordinatorImpl::WaiterList::signalAndRemoveIf_inlock
2020-10-21T15:07:38.317+0000 E REPL [conn17] ReplicationCoordinatorImpl::_doneWaitingForReplication_inlock: [opTime { ts: Timestamp(1603292856, 3), t: 1 }, minSnapshot Timestamp(0, 0), writeConcern { w: "majority", j: true, wtimeout: 0 }] !_currentCommittedSnapshot, returning false
2020-10-21T15:07:38.318+0000 E REPL [conn17] looping for 1551, waiters length 0 Note that conn17 is the update operation from the python client, which in this case is operation 1551.
Let’s go through this from the beginning:
[conn17] ReplicationCoordinatorImpl::WaiterList::add_inlock { opTime: { ts: Timestamp(1603292856, 3), t: 1 }, writeConcern: { w: "majority", j: true, wtimeout: 0 } }
[conn17] ReplicationCoordinatorImpl::_doneWaitingForReplication_inlock: [opTime { ts: Timestamp(1603292856, 3), t: 1 }, minSnapshot Timestamp(0, 0), writeConcern { w: "majority", j: true, wtimeout: 0 }] !_currentCommittedSnapshot, returning false
[conn17] looping for 1551, waiters length 1
[conn17] { opTime: { ts: Timestamp(1603292856, 3), t: 1 }, writeConcern: { w: "majority", j: true, wtimeout: 0 } }These log messages were put in _awaitReplication_inlock:
- the
ThreadWaiteris added to_replicationWaiterList(add_inlock) - at the end of that function (where mongo loops waiting for
_doneWaitingForReplication_inlock),_doneWaitingForReplication_inlockreturns false. - print out which operation we’re looping for (looping for 1551, …), and print out the waiters that are in the list.
Next:
[replexec-7] New replica set config in use: { _id: "rsvena0", version: 3, protocolVersion: 1, members: [ { _id: 0, host: "736f4cdb52d9:27017", arbiterOnly: false, buildIndexes: true, hidden: false, priority: 1.0, tags: {}, slaveDelay: 0, votes: 1 }, { _id: 2, host: "281b53d51585:27017", arbiterOnly: false, buildIndexes: true, hidden: false, priority: 1.0, tags: {}, slaveDelay: 0, votes: 1 }, { _id: 3, host: "acff78f7f7f1:27017", arbiterOnly: false, buildIndexes: true, hidden: false, priority: 1.0, tags: {}, slaveDelay: 0, votes: 1 } ], settings: { chainingAllowed: true, heartbeatIntervalMillis: 2000, heartbeatTimeoutSecs: 10, electionTimeoutMillis: 10000, catchUpTimeoutMillis: -1, catchUpTakeoverDelayMillis: 30000, getLastErrorModes: {}, getLastErrorDefaults: { w: 1, wtimeout: 0 }, replicaSetId: ObjectId('5f904dd902040f0b89191bc0') } }
[replexec-7] ReplicationCoordinatorImpl::_doneWaitingForReplication_inlock: [opTime { ts: Timestamp(1603292856, 3), t: 1 }, minSnapshot Timestamp(0, 0), writeConcern { w: "majority", j: true, wtimeout: 0 }] haveTaggedNodesReachedOpTime returned true
[replexec-7] ReplicationCoordinatorImpl::WaiterList::signalAndRemoveIf_inlock { opTime: { ts: Timestamp(1603292856, 3), t: 1 }, writeConcern: { w: "majority", j: true, wtimeout: 0 } }
[replexec-7] ReplicationCoordinatorImpl::WaiterList::signalAndRemoveIf_inlock- Replica set reconfiguration occurs.
_wakeReadyWaiters_inlockis called, which callssignalAndRemoveIf_inlock_doneWaitingForReplication_inlockreturns true for our operation’s waiter (notice it reached the end, and calledhaveTaggedNodesReachedOpTime)- that waiter is removed from
_replicationWaiterList
Next:
[conn17] ReplicationCoordinatorImpl::_doneWaitingForReplication_inlock: [opTime { ts: Timestamp(1603292856, 3), t: 1 }, minSnapshot Timestamp(0, 0), writeConcern { w: "majority", j: true, wtimeout: 0 }] !_currentCommittedSnapshot, returning false
[conn17] looping for 1551, waiters length 0This comes again from _awaitReplication_inlock:
- The condition variable was signalled by
signalAndRemoveIf_inlock. - Execution continues to the top of the while loop, and
_doneWaitingForReplication_inlockreturns false. - There are no more waiters in
_replicationWaiterList. - This thread will wait on the condition variable and never return.
The bug
Visualized (where the left side is the operation thread, and the right side is the thread processing the replSetReconfig command):
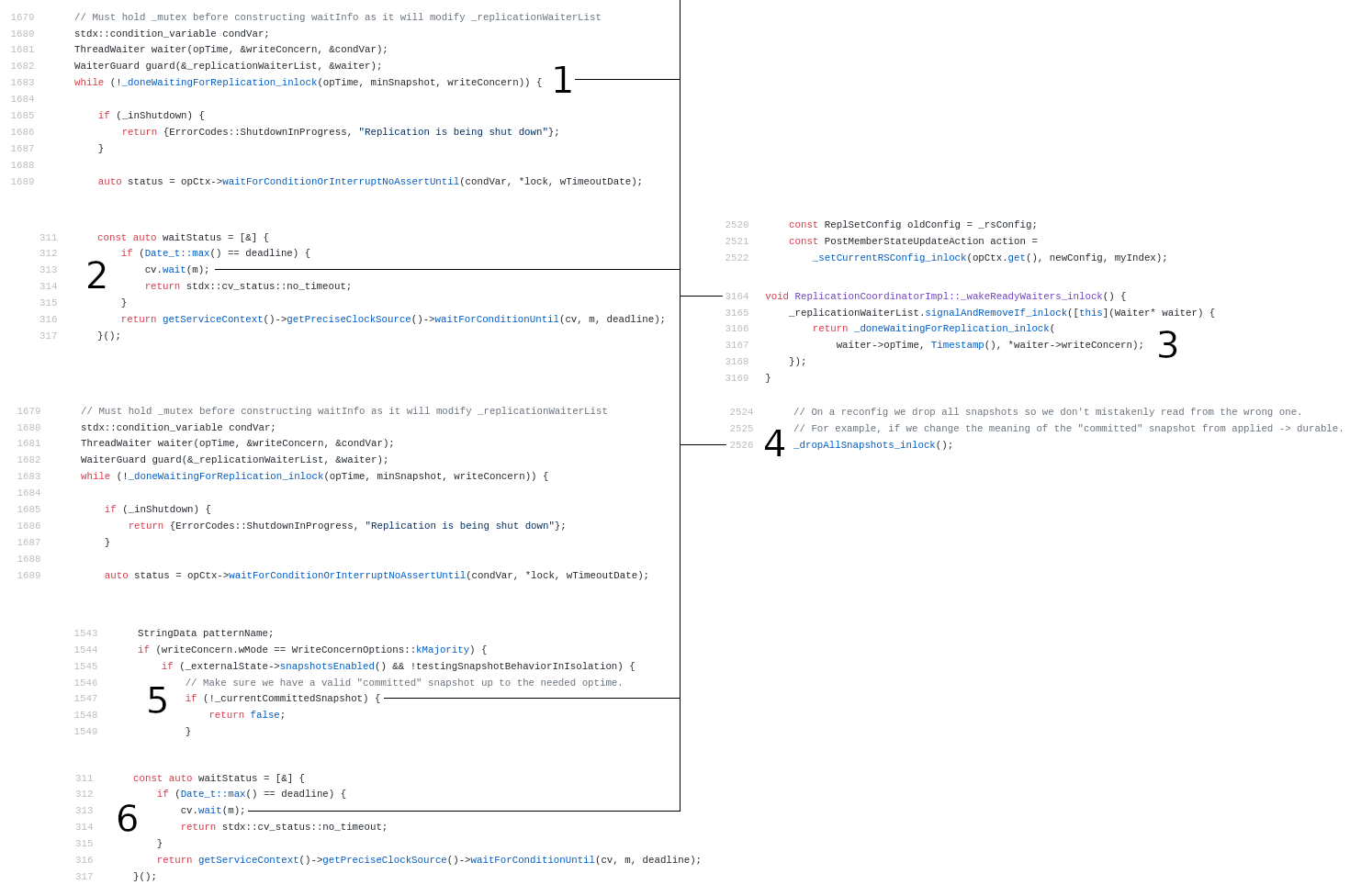
Below is the sequence that causes this bug, where blue represents the operation thread, and red represents the replSetReconfig thread.
_doneWaitingForReplication_inlockreturns false- wait on condition variable
_doneWaitingForReplication_inlockreturns true- set
_currentCommittedSnapshot = boost::none - in
_doneWaitingForReplication_inlock, check_currentCommittedSnapshotand return false because it’sboost::none - wait forever on condition variable
The fix
The problem exists because _currentCommittedSnapshot was zeroed out temporarily – my proposal for a fix is to add a wait until _currentCommittedSnapshot is non-null again:
1680 stdx::condition_variable condVar;
1681 ThreadWaiter waiter(opTime, &writeConcern, &condVar);
1682 WaiterGuard guard(&_replicationWaiterList, &waiter);
1683 while (!_doneWaitingForReplication_inlock(opTime, minSnapshot, writeConcern)) {
...
1689 auto status = opCtx->waitForConditionOrInterruptNoAssertUntil(condVar, *lock, wTimeoutDate);
1690 if (!status.isOK()) {
1691 return status.getStatus();
1692 }
...
+1711 // If a replSetReconfig occurred, then all snapshots will be dropped.
+1712 // `_doneWaitingForReplication_inlock` will fail if there is no current snapshot, and
+1713 // if this thread's waiter was signaled and removed from the wait list during
+1714 // replSetReconfig we will enter waitForConditionOrInterruptNoAssertUntil above and
+1715 // condVar will never be notified.
+1716 //
+1717 // If it's null, wait for newly committed snapshot here.
+1718 while (!_currentCommittedSnapshot) {
+1719 opCtx->waitForConditionOrInterrupt(_currentCommittedSnapshotCond, *lock);
+1720 }
1721 }I’ve tested this, and it successfully resumes after a replSetReconfig:
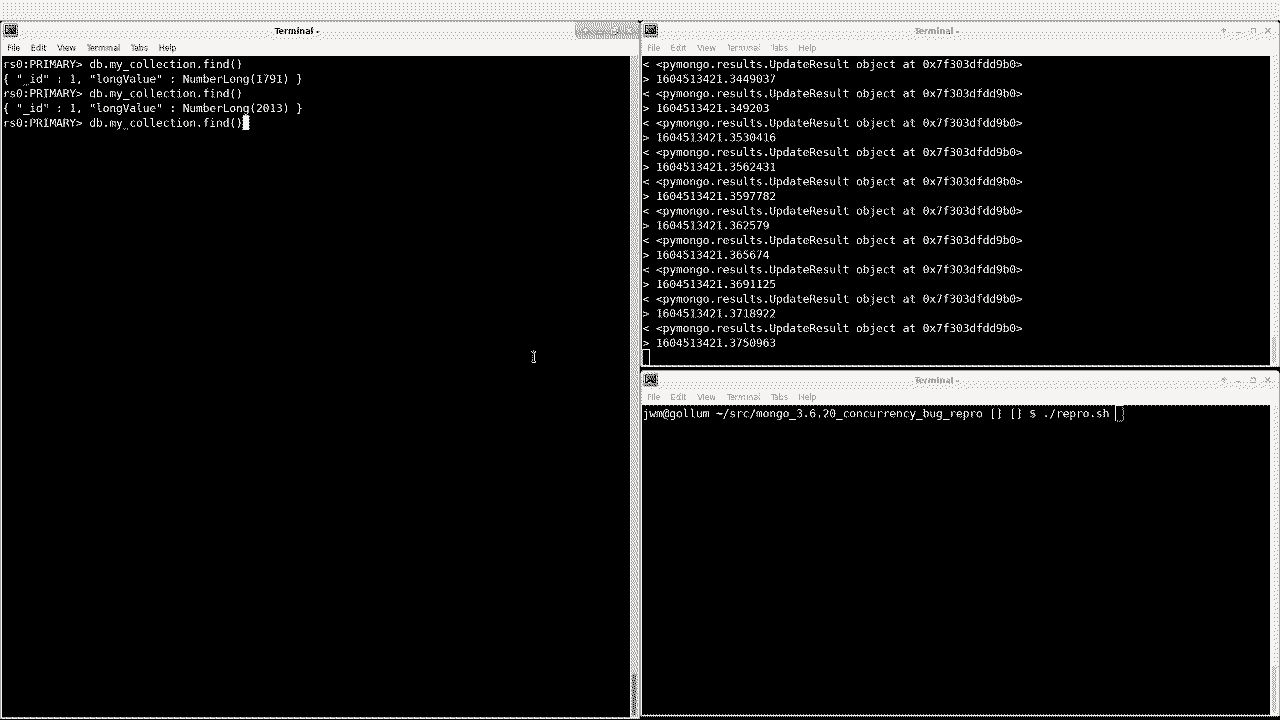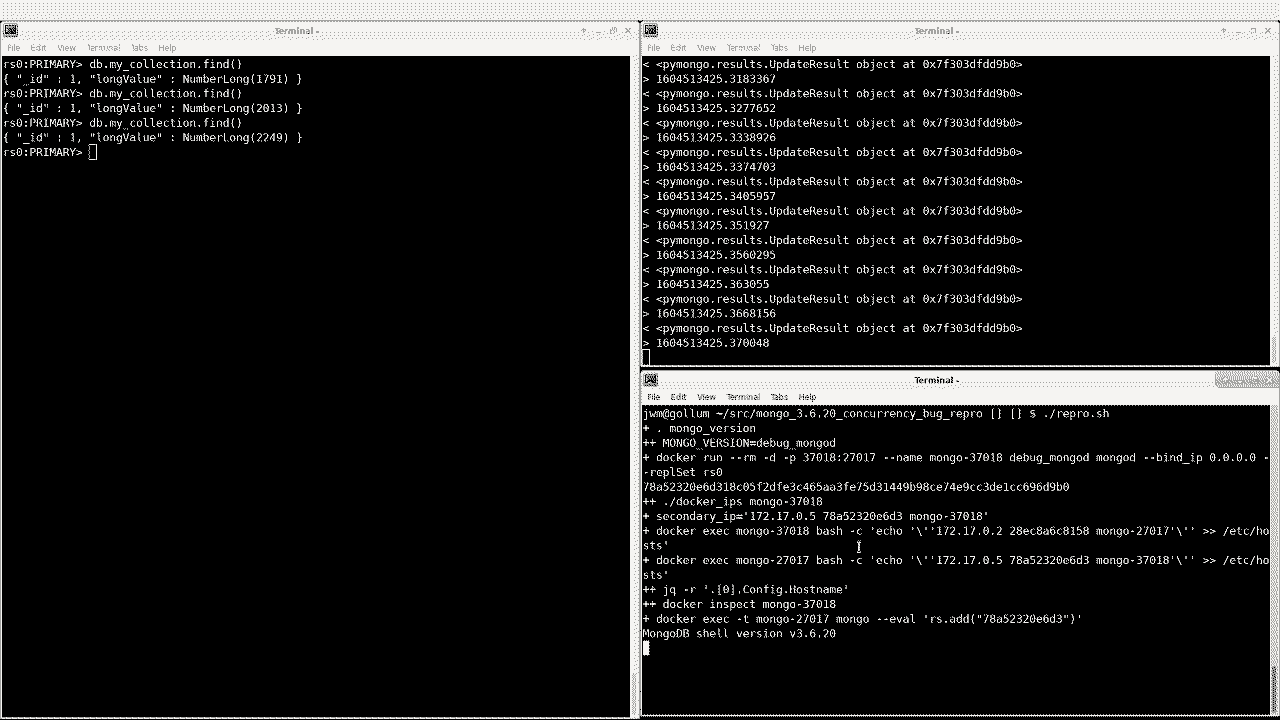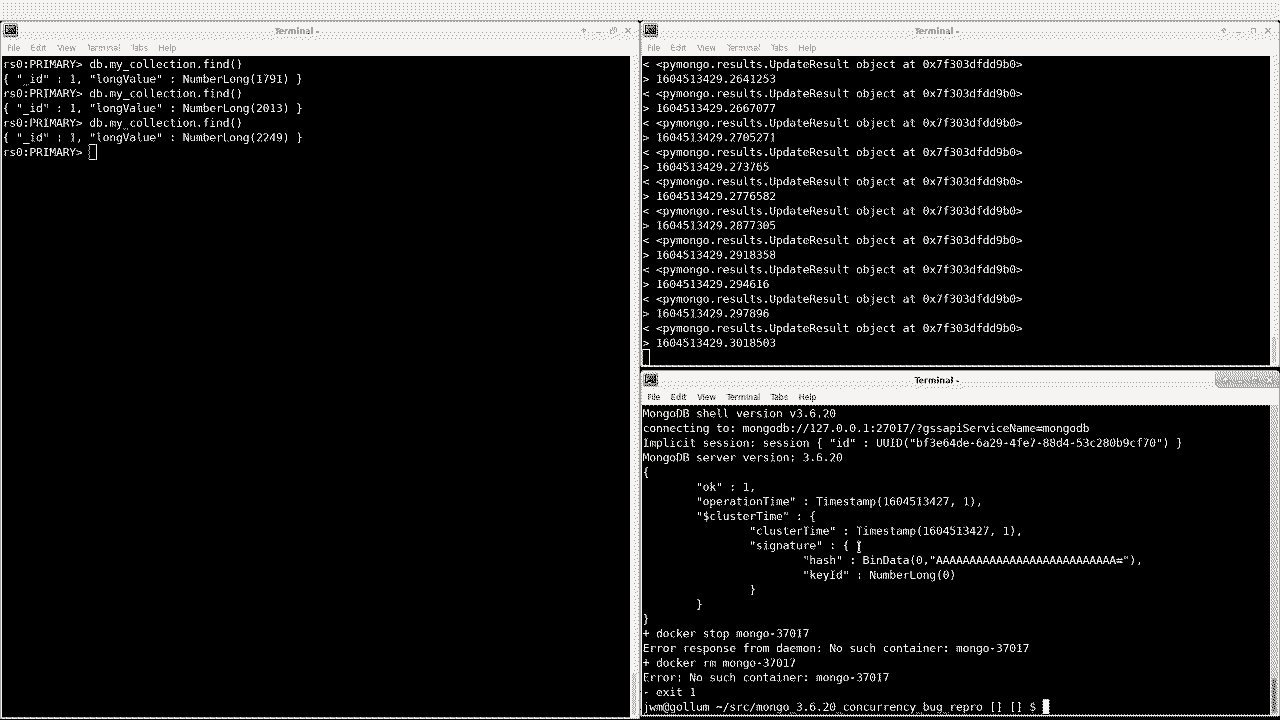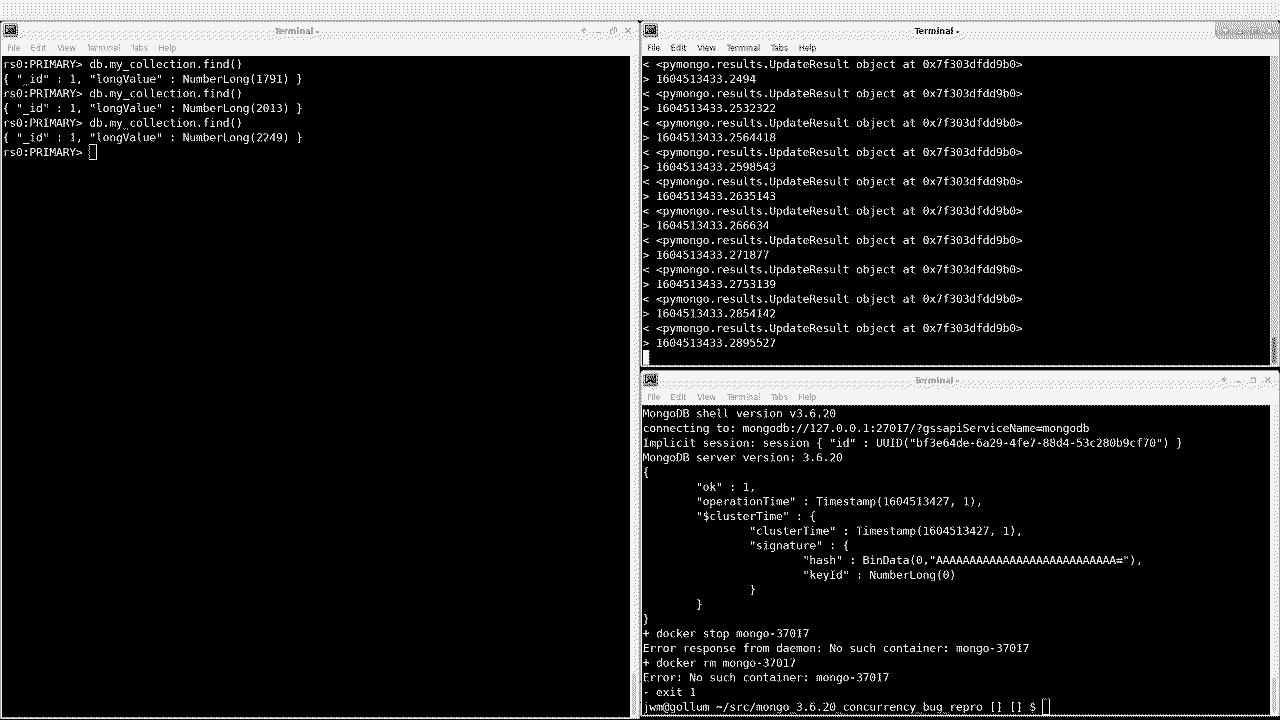
Note that there is still a pause during the reconfigure, but it eventually resumes.
Filing a ticket
I was also able to reproduce this bug against versions 4.0.0 and 4.0.1, but not 4.0.2. I looked at all the commits between 4.0.1 and 4.0.2 and this one looks like it would solve this problem by removing one of the necessary conditions: that the waiter was removed from the list by something other than the waiter guard. That looks like a much cleaner fix than my proposal.
In any case, I opened an issue on Mongo’s Jira, and the story continues there!