To 404 or not to 404?
In a REST API system, what should the DELETE API return if the resource being deleted doesn’t exist: “200 OK” or “404 Not Found”? It seems like a minor design choice, but we had a surprisingly contentious debate over the correct behaviour. There are arguments for both ways and they go deep into how you build fault-tolerant systems.
Differentiate between 200 and 404
The first option is to return 200 OK only if the resource was found and successfully deleted, otherwise return 404 Not Found if it didn’t exist in the first place. Arguments for this option:
- It’s consistent with a GET request on the same URL.
- It tells you if anything was actually deleted on the server side. If you know that something should be there, but you receive a 404 instead of a 200, that could mean you mistyped the URL.
Always return 200
The other option is to return 200 OK in both cases. Arguments for this option:
- Think of the delete API not as an action, but as a declaration of a desired end state: on completion, the resource should not exist. Whether the resource existed before doesn’t matter; as long as it doesn’t exist after the API is sent, then it’s a success.
- Clients that want to use the API this way could just interpret both 200 and 404 responses as successful, but it would be simpler if they didn’t have to.
- In the event of retrying the request (e.g. due to some network error), we may not be able to differentiate between “nothing was there” vs. “it was there and deleted on the first attempt, then not found on the retry.” If a client were relying on this information to be accurate, then this could be a problem! To avoid misleading the client, we should just always return 200.
The last point is rather subtle and is explored in detail below.
Idempotency and Network Retries
REST is built on HTTP, which is a protocol that goes over a possibly unreliable network. The HTTP 1.1 specification says DELETE requests should be idempotent, which means:
The side-effects of N > 0 identical requests is the same as for a single request.
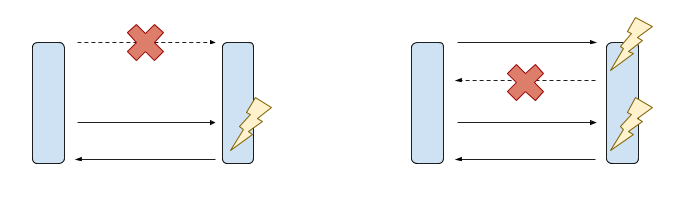 Two possible retry scenarios between client and server. Left — Initial request is lost; 1 action is performed. Right — Initial response is lost; 2 actions are performed.
Two possible retry scenarios between client and server. Left — Initial request is lost; 1 action is performed. Right — Initial response is lost; 2 actions are performed.
The idea behind idempotency is to be resilient to network errors. Imagine you send a request but receive a server error or timeout in response (or no response at all). What do you do? You would like to retry that request… but is it safe to do so? If the server never received your request, then no action was performed, so there’s no harm in re-sending it. But it’s also possible that the server received and fulfilled your original request and only the response was lost over the network. This means retrying it could potentially execute the same action twice! For an idempotent request, it is always safe to retry, because the request has the same effect whether it is executed once, twice, or many times. Clearly, this is a desirable behaviour to have in an unreliable network!
Do different responses violate idempotency?
Consider an update API, where the server responds with a modified count, describing the number of objects actually modified by that request. (An example is the number of rows modified by a database command.) It’s possible to make this update API idempotent with regards to the server state (e.g. by describing the desired end state in the payload). But it’s not possible for the modified count to be the same in all cases! If the same request is executed twice, the modified count is non-zero in the first response, but zero in the second!
The same applies to the return code of a DELETE request that differentiates between 200 and 404; the first response will be 200 (deleted), and the second will be 404 (not found). In general, any response that describes how the server state changed may differ between multiple executions of the same request.
Any information that describes how the server state changed may differ between multiple executions of the same request.
Does this violate idempotency? Technically, the modified count is metadata about the request, not a “side-effect” as described in HTTP 1.1, so it does not violate it! (If that’s not convincing enough, then consider that there are many more response headers that would differ between the first execution and the second, but these differences don’t violate idempotency either.) In fact, RFC 7231 section 4.2.2 explicitly states that “the response might differ.” So both designs are idempotent and idempotency alone is not enough to argue for always returning 200.
Can you trust the response?
In the broader picture, the goal of idempotency is to enable safe and automatic retries of requests. Here, we have to be careful. Say there is no response to a request, so the request is retried (possibly by an intermediate node). If a response is then received saying “nothing was changed,” it’s still possible that something did change on the original request — we never received the original response, so we don’t know! If clients cannot rely on the response to accurately describe what changed, then this would seem to be a major point in favour of not returning such information at all — why return uncertain information? All is not lost though! If the client can be certain that no retry occurred, then the response can be trusted.
The difference may seem academic, but back in 2017, we encountered this scenario in a real world application that needed resiliency to MongoDB primary stepdowns. This was done by adding automatic retry to MongoDB queries just as described above and as recommended by A. Jesse Jiryu Davis, a MongoDB staff engineer and co-author of their Server Discovery And Monitoring Spec. Safe retry requires updates to be idempotent and this was achievable, but our application also had a cache optimization that depended on knowing if an update to MongoDB successfully modified any documents or not. The MongoDB response contains a modified count, but an automatic network retry would make it impossible to trust it. Fortunately, since the retry was invoked by our own code, we knew when we could trust this number, and therefore knew when it was possible to apply our cache optimization!
If you can be certain that no retry occurred, then the response can be trusted.
Conclusion
There doesn’t seem to be a clear winner or loser between the two choices. If you are a purist or designing for a system where retries are both automatic and unknowable, then you may lean towards “always returning 200” to avoid any reliance on potentially inaccurate information. If you are a pragmatist or designing for a system where retries are controlled manually, you may prefer “differentiating between 404 vs 200” because having possibly inaccurate information is better than no information at all. Just keep in mind that the information is only sometimes useful, and sometimes incorrect. On the other hand, it is only sometimes incorrect, and sometimes useful. What’s your outlook: is the glass half-empty or half-full? 🥤:)