Fast Gaussian-distributed Random Numbers

Recently, profiling showed me that most of the time in the microbenchmark I was running was spent generating the stream of random numbers using Random.nextGaussian. I didn’t need a high-quality Gaussian distribution—I just wanted some moderately realistic numbers—so, mostly for fun, I set about writing my own Gaussian-distributed number generator based on the cheaper Random.nextLong, using techniques described by John D. Cook.
Here’s how it works.
Gaussians Everywhere!
Our technique rests on the Central Limit Theorem, which states that if you add enough random variables together, you get a Gaussian distribution regardless of the distributions of the original variables.
Yep, you can generate Gaussians out of thin air just by adding together whatever random variables you happen to have lying around. In particular, we can add together a collection of uniformly distributed random variables to produce an approximation of a Gaussian. This is handy, because those are relatively cheap to generate.
How many should we add together? Well, the more the better; but it turns out we don’t need very many in practice: about half a dozen.
Below is a collection of graphs from Wikipedia showing what happens if you roll n dice. For n=1, the probabilities all equal 1/6. Below that, for n=2, rolling a 7 is most common, with the probability falling off for lower and higher sums. By the time n reaches 5, the probability distribution is already a close approximation of a Gaussian curve, and the approximation gets closer and closer as n increases.
{kind=link}

Note that the above graphs get wider as n increases; mathematically, we say the variance is increasing. For n=1, there are just six bars, while for n=5 there are thirty, which is five times more. Also, note that the average value rolled also increases: for n=1, the mean is 3.5, while for n=5, it’s 17.5, which is five times larger.
In fact, these are two general features of uncorrelated random variables:
1. The variance of the sum equals the sum of the variances.
2. The mean of the sum equals the sum of the means.
It can be shown that a random variable uniformly distributed between -0.5 and +0.5 has a mean of 0 and a variance of 1/12. Therefore, if you add twelve such variables together, you get a mean of zero and a variance of 1, and the Central Limit Theorem ensures that the resulting sum has very nearly a Gaussian distribution.
Lo and behold! These specs match those of the Random.nextGaussian method!
So this is what we’re going to do: add twelve uniformly-distributed random numbers.
Bit-Twiddling Tricks
There’s a simple, efficient way to generate twelve independent uniformly distributed random variables, from one call to Random.nextLong(). That call returns a uniformly distributed 64-bit number; we’re going to treat it as twelve 5-bit numbers (plus a few leftover bits).

Our objective is to add these twelve numbers as quickly as possible. Of course, we could take the bottom five bits, then add in the next five, and so on. This would require eleven adds, shifts, and masks.
But we can do better.
Suppose we mask and shift these bits, to separate alternate 5-bit numbers from each other:

If we add these two giant numbers, the effect is the same as adding six pairs of small numbers:

It’s possible for one or more of these individual sums to carry, if the result is more than 31; this occurs in our example with 28+29 = 57. The good news is that we are guaranteed to have five bits of zeros to the left of each sum, which is plenty of room for a 1-bit carry. That means the sums will never interfere with each other. We’ve turned our CPU into a highly parallel adding machine!
Next, we can apply the same concept if we take this number and shift it right by 40 bits and add it to itself:
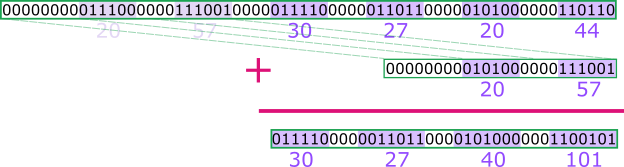
Again, the sums can carry, but we still came in with four bits of padding between the numbers, which is still plenty for a 1-bit carry.
Continuing in this fashion twice more, we can finish summing these numbers before we run out of padding bits, meaning the grand total (198) is, indeed, the correct total for the original numbers. However, instead of eleven shifts, masks, and adds, we’ve done it with four shifts, four adds, and just three masks. That’s a three-fold improvement!
What about the mean and variance?
Hold on a sec: we wanted to add twelve numbers between -0.5 and +0.5, but we’ve actually added twelve numbers between 0 and 31. Because of this, we have two problems:
- The mean of our twelve numbers is 186, while it should be zero. We can fix this by subtracting 186 from the sum.
- The variance of our twelve variables was 31 times wider than it should have been. We can fix this by dividing the sum by 31.
So with one extra subtract and one divide by 31, we now have a gaussian-distributed random variable with the desired properties.
Here’s the resulting bit-twiddling code:
static double quickGaussian(long randomBits) {
long evenChunks = randomBits & EVEN_CHUNKS;
long oddChunks = (randomBits & ODD_CHUNKS) >>> 5;
long sum = chunkSum(evenChunks + oddChunks) - 186; // Mean = 31*12 / 2
return sum / 31.0;
}
private static long chunkSum(long bits) {
long sum = bits + (bits >>> 40);
sum += sum >>> 20;
sum += sum >>> 10;
sum &= (1<<10)-1;
return sum;
}
static final long EVEN_CHUNKS = 0x7c1f07c1f07c1fL;
static final long ODD_CHUNKS = EVEN_CHUNKS << 5;
Performance
In my tests, quickGaussian is 2.7x faster than nextGaussian. Most of the remaining time is spent in Random.nextLong; the time spent making the numbers Gaussian is small in comparison. (I also have an implementation using Marsaglia’s Xorshift+ algorithm that makes it a further 4x faster, but that’s another blog post.)
…but don’t do this if the numbers matter!
Note that this technique is only capable of generating 373 distinct numbers. If you need more variety, you could call this multiple times and average the results, but that would obviously cut into its performance advantage, and it wouldn’t give the same kind of guarantees as nextGaussian.
In short, you probably don’t want to use this technique, but it worked for me, and it was fun to write.